Like many of the other British Ecological Society journals, MEE has recently transitioned to a double anonymous peer review model. This decision was made after the results of a recent study conducted from 2019-2022 on the Journal of Functional Ecology. Below are some frequently asked questions to help with the preparation of your submission to Methods in Ecology and Evolution.
Can I publish a preprint of my manuscript?
There is no issues with publishing a preprint of your article before you submit to us. We don’t expect this to compromise the assessment and review of your manuscript.
Can I include a second language abstract at submission?
Yes! We encourage second language abstracts at any stage of submitting a manuscript. If you wish to provide one before your manuscript the final decision please ensure it’s included the ‘Title page’ document instead of the main manuscript.
Can I still submit a manuscript if my R package if its already on the CRAN Library?
Similar to preprints, you can still submit a manuscript to us even if there is associated code or data already in the public domain. Just let us know at submission and provide an anonymised version of your data/code for review.
Do I need to anonymise my manuscript in revision?
We do ask that manuscript are kept anonymous until a final decision is made. If you are submitting a revision please include your identifying information in a title page document.
Do I need to anonymise self-citations?
It’s best not to anonymize these using e.g. (Anonymous, 2010) for previously published articles as this can draw attention to you as an author.
It can be done for referencing data archives as long as it is anonymized as well (see below on how)
Sensitive data
If you have any sensitive data which you are not able to archive please state so in your data availability statement and cover letter. If possible please provide your data review to support your submission. Access to this data will only be provided to editors and reviewers and not made public. If you have any queries or concerns about this please contact the journal.
How should I supply data at submission
You can supply are various data repositories which are available which accommodate data that is private for peer review.
You are welcome to submit your data either as a uploaded document or using a data repository. If uploading your data to a repository please check that they support ‘private for peer review’.
Do I need to anonymise my revised manuscript?
Until a final decision on your manuscript has been passed we ask that any revised article also be anonymised. Be careful when putting together as ‘response to reviewer’ documents that they don’t include any identifying information.
Several data archiving platforms with this option can be found here:
| Repository | Data type | Description |
|---|---|---|
| Dryad/Zenodo* | General/Code | Used for all types of data associated with published papers. The BES is integrated with Dryad covering all cost of archiving the data (up to 20GB) and providing a streamlined process. For information on how to anonymise your dataset on Dryad see here, for Zenodo see below |
| Figshare | General | Suitable for archiving all data types associated with published papers. Figshare supports the archiving of any material relevant to scholarly advancement such as posters, presentations code. For information on how to anonymise your dataset on with Figshare see here |
| OSF | General/code | OSF is a free and open source project management tool which allows for the archiving of many data types audiovisual data and source code To anonymise your code for review see here |
| Github | Code | Cloud based server which allows for the storage of source code To anonymise your data for review see here |
| Biostudies | General/Genomic | The BioStudies database holds descriptions of biological studies, links to data from these studies in other databases at EMBL-EBI or outside. To anonymise your data for review see here |
| Dataverse | General/code | The Dataverse Project is an open source web application to share, preserve, cite, explore, and analyze research data. To anonymise your data for review see here |
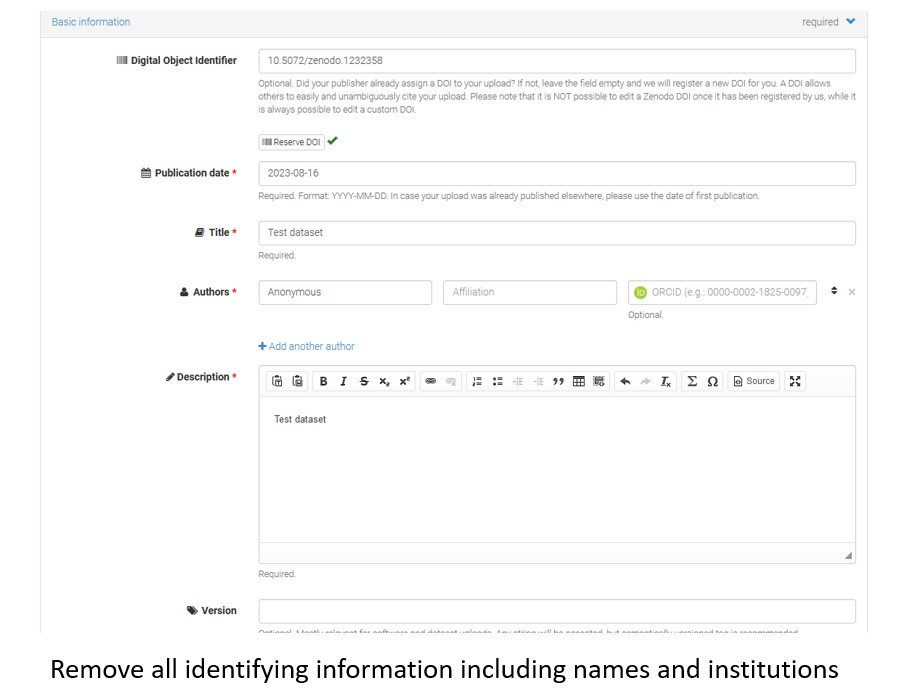
When anonymising data stored on Zenodo this can be done in two methods. One way is to list the author/creator names, institutions and any identifying information as ‘Anonymous’ and keep the dataset public.
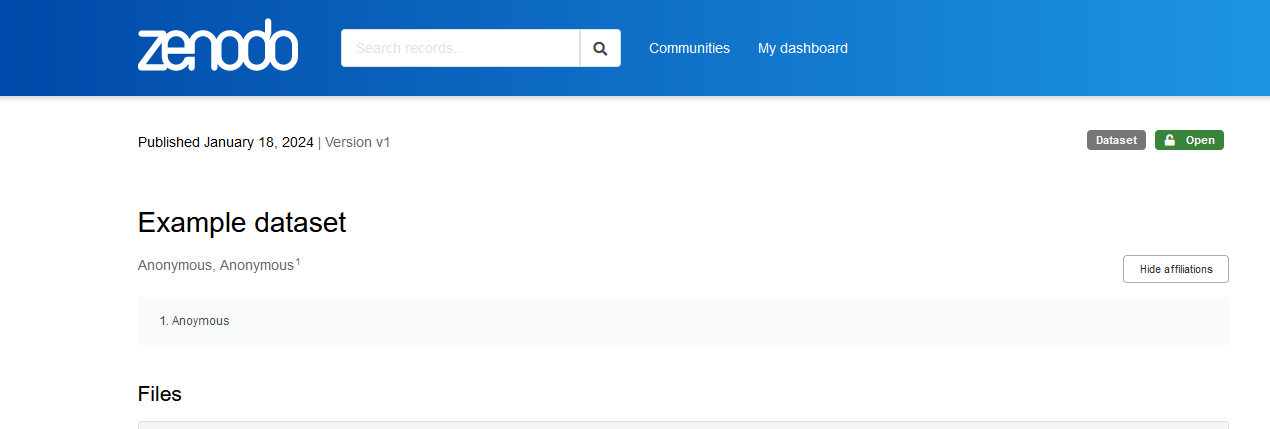
Alternatively if you would prefer to have your dataset private you can restrict access.
The process of requesting data in zenodo does reveal the requester’s email address and also shows the user name of the uploader. To prevent this from affecting double anonymous peer review please provide a link to your data from Zenodo using the following steps:

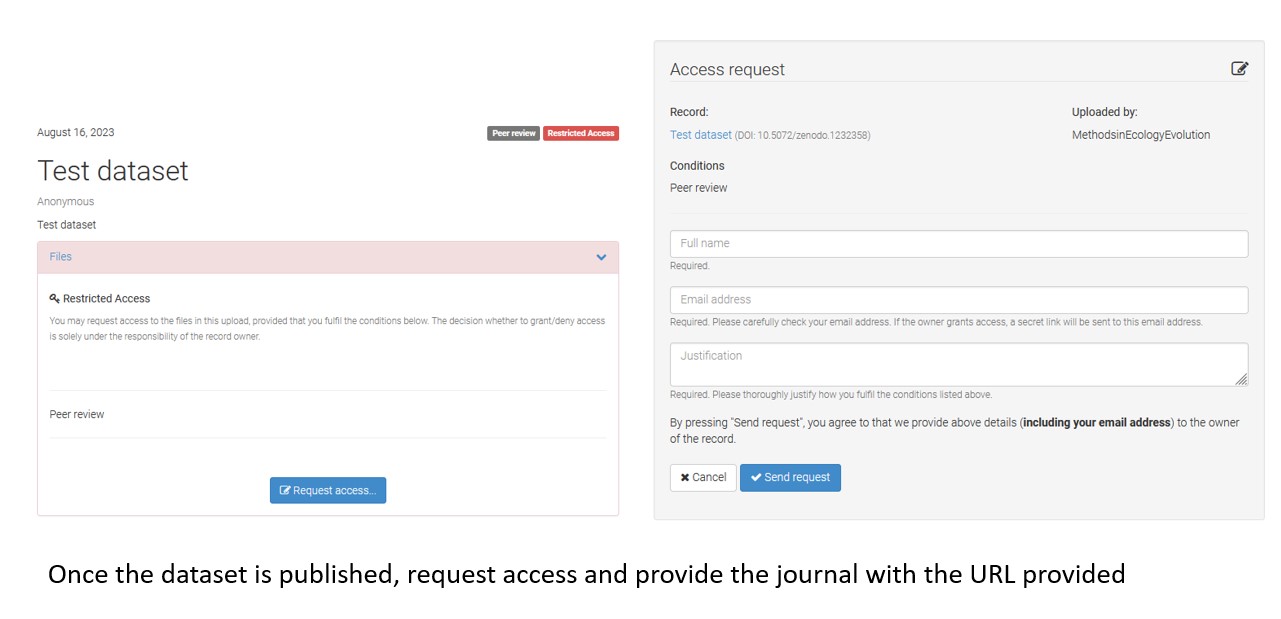
If you have any questions about submitting to our journal please feel free to contact the journal via email
