Post provided by Gabriela Nunez-Mir
 A search of almost any topic on Google Scholar promises to return tens of thousands of hits in less than a second. The first step in any research endeavour is to wade through the titanic amounts of articles available to become acquainted with the existing knowledge. For many people it’s one of the most dreadful and tedious parts of the scientific process.
A search of almost any topic on Google Scholar promises to return tens of thousands of hits in less than a second. The first step in any research endeavour is to wade through the titanic amounts of articles available to become acquainted with the existing knowledge. For many people it’s one of the most dreadful and tedious parts of the scientific process.
But what if we could streamline/facilitate this step by automatizing parts of it? Automated content analysis (ACA) gives us the opportunity to do just that. ACA – a text-mining method that uses text-parsing and machine learning – is able to classify vast amounts of text into categories of named concepts. It can then quantify the frequency of those concepts and the relationships among them.
The Big Literature Challenge
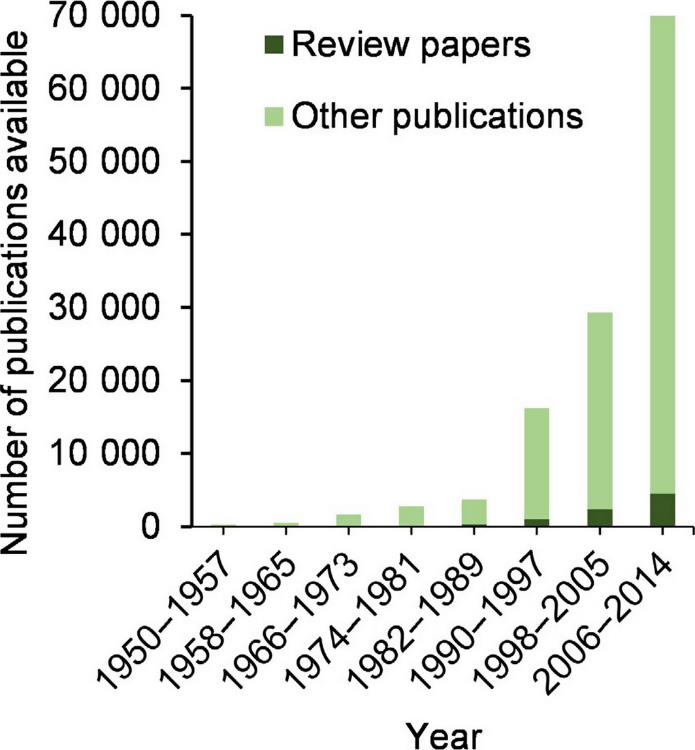 The amount of literature being produced and made readily available has grown exponentially in the past few decades. A basic search on Web of Science for articles classified under the topic category of ‘ecology’ from 1950 to 2014 found 125,000 research articles, among which 70,000 occurred in the last 7 years.
The amount of literature being produced and made readily available has grown exponentially in the past few decades. A basic search on Web of Science for articles classified under the topic category of ‘ecology’ from 1950 to 2014 found 125,000 research articles, among which 70,000 occurred in the last 7 years.
Just like the phenomenon of big data, the issue of “big literature” has come to the forefront in recent years. Big literature refers to the challenges presented by the large volumes of scientific literature generated at such high velocities, that they become difficult to manage, process and comprehend. The repercussions of this issue are illustrated in the figure above, as the proportion of review papers in comparison to other scientific publications becomes smaller with time.
What is ACA?
Automated Content Analysis (ACA) is a method performed by algorithms that use probabilistic topic or concept-mapping models to identify and describe the major themes in a body of text, the frequency at which they appear and the relationships among them. To do this, ACA detects groups of words that “travel together” (i.e. occur frequently in the text together), and therefore are likely to represent or express a common theme or idea. These groups of words, called concepts, are the cornerstone of ACA. They are not only used to identify the major topics in a body of text, but they are also used to classify the literature. In other words, segments of text in which a given concept occurs will be classified under said concept – imagine marking lines of text with a highlighter every time a concept occurs. As a result, ACA returns an indexed version of the body of text that allows the program to obtain the frequency of these concepts and how often they occur in the same text segment.
Benefits of ACA
ACA provides unique contributions that the traditional manual literature synthesis methods (e.g. narrative reviews, vote-counting) are unable to offer:
 Reduces the cost and time of analysis – ACA systems have been found to be able to process up to 300MB of text data per analysis (approximately 8,500 articles assuming 5,000 words per article)
Reduces the cost and time of analysis – ACA systems have been found to be able to process up to 300MB of text data per analysis (approximately 8,500 articles assuming 5,000 words per article)- Produces both quantitative and qualitative results
- Mitigates human influence, bias and subjectivity
- Uses concepts instead of single words – accounts for semantic and linguistic complexities, such as synonyms, co-occurrence frequencies and sentence construction
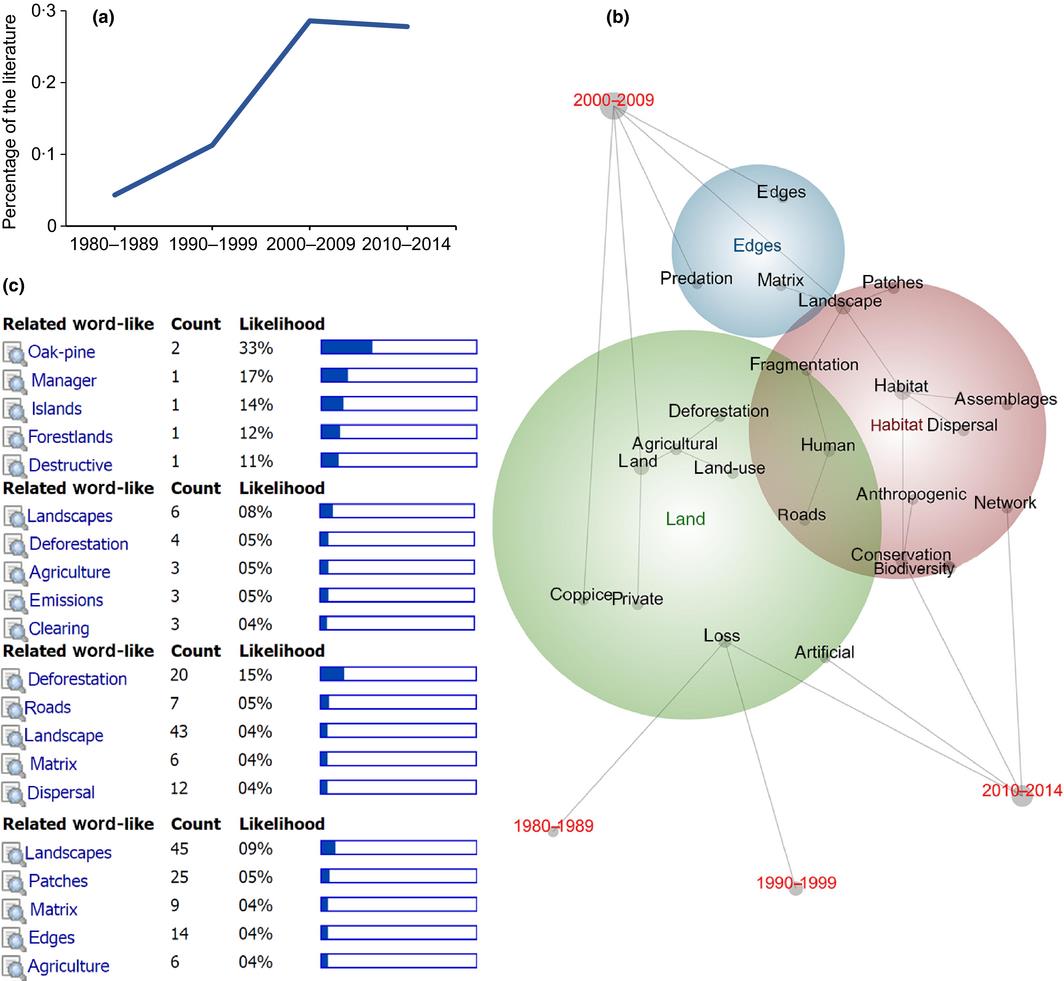
- Generates graphic summaries of results (pictured above)
The ACA Process
The fundamental process of ACA can be divided into three stages: concept identification, concept definition and text classification.
Concept Identification
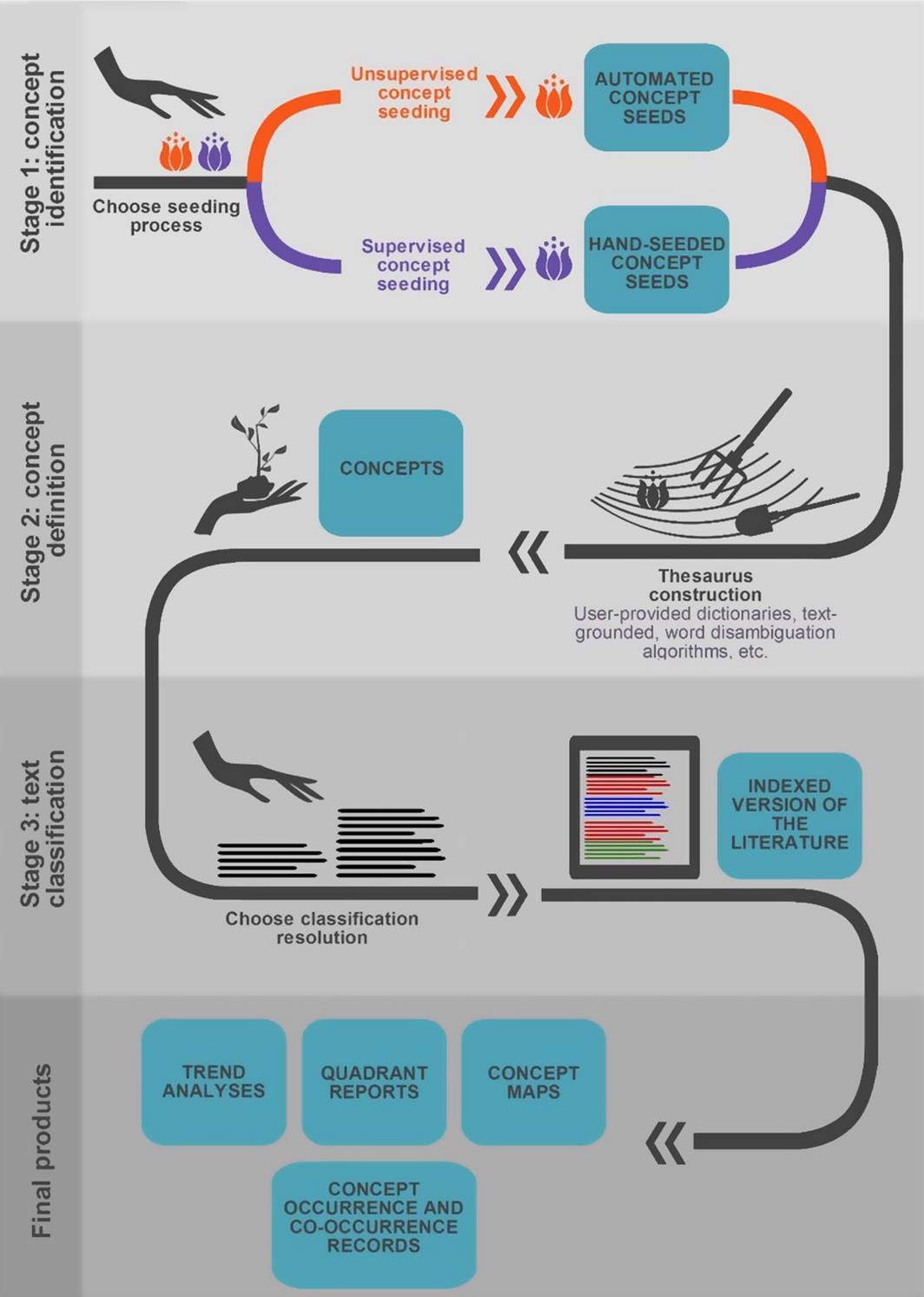
In the first stage the concepts by which the literature will be classified are determined through the use of concept seeds. Concept seeds are single words that occur frequently in the literature and are therefore most likely to represent important concepts.
Concept Definition

During the second stage a thesaurus is compiled for each concept. Thesaurus building can be accomplished through different methods depending on the design and capacity of the ACA software system used. At the end of this stage, ACA creates a set of predominant concepts, each defined by a thesaurus.
Text Classification
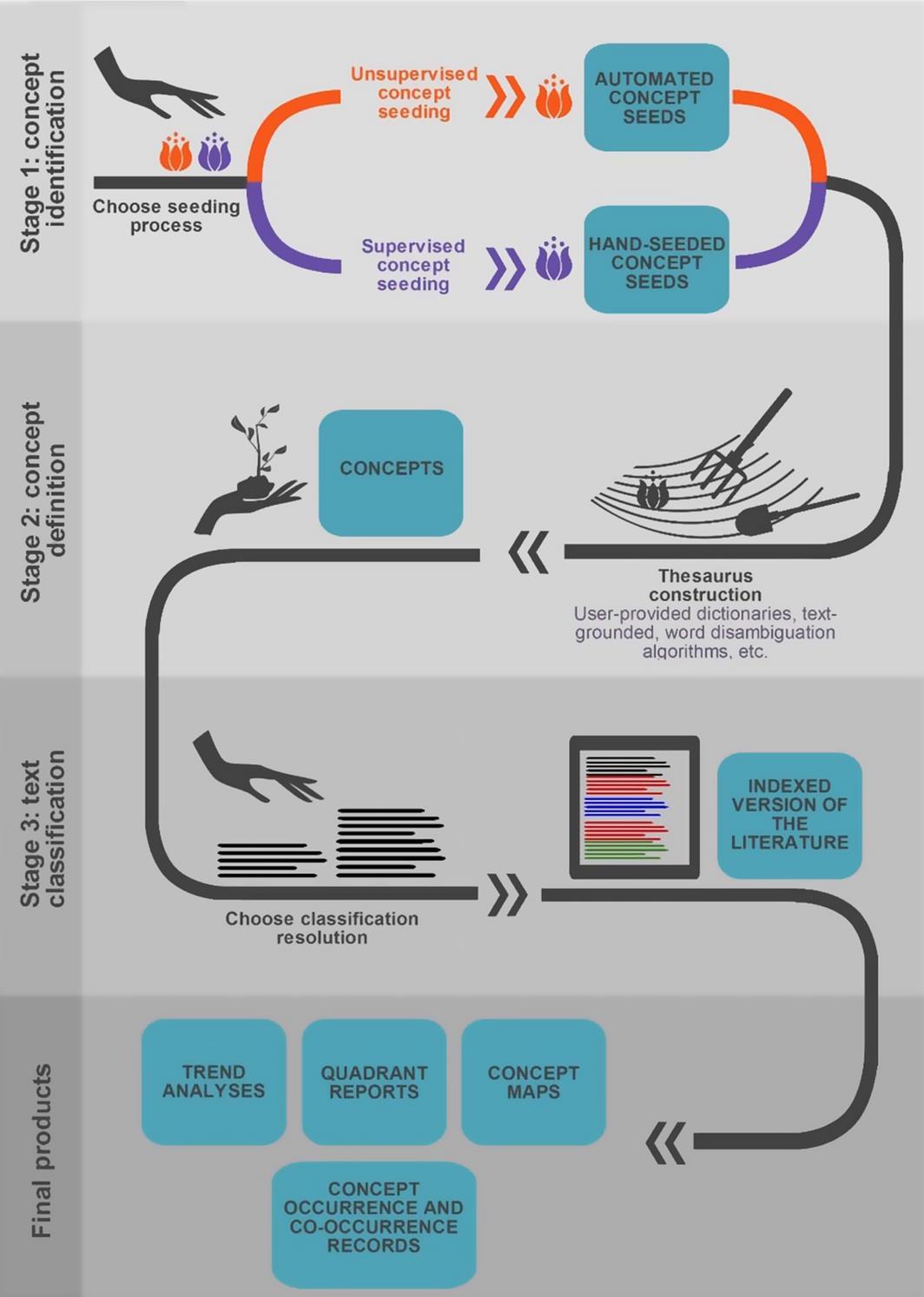
In the third and final stage of ACA the literature is classified by the concepts identified and defined in the two previous stages. The categorization of the literature is generally performed at high resolutions (e.g., by 2- or 3-sentence segments).
ACA in Action
A wide range of studies and reviews have been performed and written using ACA tools. The examples below show the breadth of topics that ACA can be applied to.
- Bengston, D.N.& Xu, Z. (2006) Changing National Forest Values: a content analysis. Research Paper NC-323. US Department of Agriculture, Forest Service, North Central Forest Experiment Station, Paul, Minnesota, USA.
- Cretchley, J.,Rooney, D. & Gallois, C. (2010) Mapping a 40-year history with Leximancer: themes and concepts in the Journal of Cross-Cultural Psychology. Journal of Cross-Cultural Psychology, 41, 318–328.
- Grech, M.R.,Horberry, T. & Smith, A. (2002) Human error in maritime operations: analyses of accident reports using the Leximancer tool. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, pp. 1718–1721. SAGE Publications, Thousand Oaks, California, USA.
- Nunez-Mir, G. C., Iannone III, B. V., Curtis, K., & Fei, S. (2015). Evaluating the evolution of forest restoration research in a changing world: a “big literature” review. New Forests, 46(5-6), 669-682.
- Nunez‐Mir, G. C., Iannone, B. V., Pijanowski, B. C., Kong, N., & Fei, S. (2016). Automated content analysis: addressing the big literature challenge in ecology and evolution. Methods in Ecology and Evolution.
- Nunez-Mir, G.C. J. M. Desprez, B. V. Iannone III, T. Clark, and S. Fei. Is forestry research addressing socioecological challenges? Journal of Forestry (Accepted)
As evidenced by its use in other fields, such as the social sciences and medical research, the ACA approach may fill an important methodological gap in literature review in our field. In the same way that innovative big data tools have unleashed our abilities to harness the knowledge contained in massive datasets, ACA can help environmental researchers harness the wealth of information contained within big literature. We invite researchers to take the plunge and explore the possibly uncharted territories of big literature in ecology and evolutionary biology through this innovative tool.
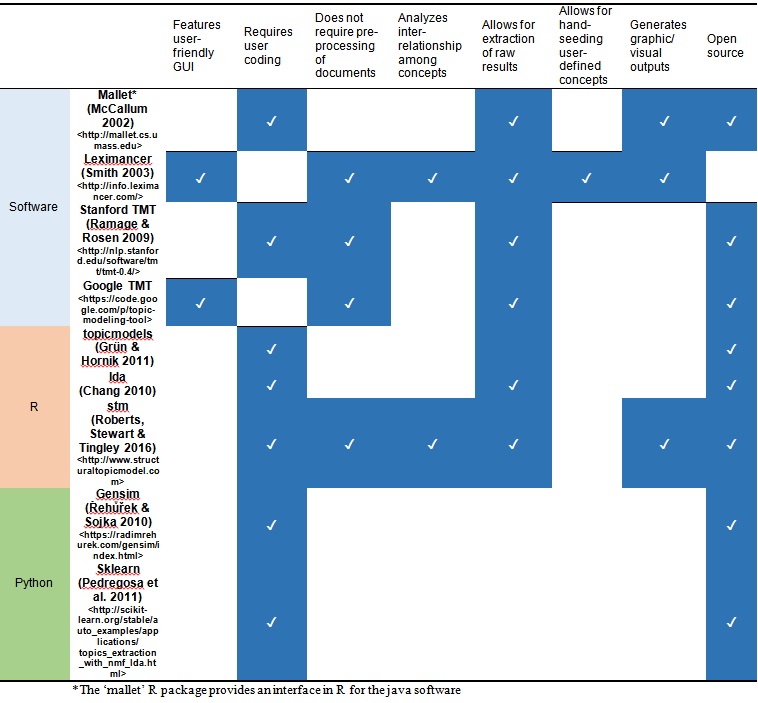
ACA Tools Available
ACA is not a single piece of software or code. If you’re interested in using these tools there are a lot of options, many of them open source. The following table highlights some of the available software, R packages and Python libraries with which to perform ACA:
To find out more about Automated Content Analysis, read our Methods in Ecology and Evolution article ‘Automated content analysis: addressing the big literature challenge in ecology and evolution’.

I have used this extensively for some of my research. This is really helpful as an article.