Post provided by CHRIS TERRY
Artificial intelligence (or AI) is an enormously hot topic, regularly hitting the news with the latest milestone where computers matching or exceeding the capacity of humans at a particular task. For ecologists, one of the most exciting and promising uses of artificial intelligence is the automatic identification of species. If this could be reliably cracked, the streams of real-time species distribution data that could be unlocked worldwide would be phenomenal.
 Despite the hype and rapid improvements, we’re not quite there yet. Although AI naturalists have had some successes, they can also often make basic mistakes. But we shouldn’t be too harsh on the computers, since identifying the correct species just from a picture can be really hard. Ask an experienced naturalist and they’ll often need to know where and when the photo was taken. This information can be crucial for ruling out alternatives. There’s a reason why field guides include range maps!
Despite the hype and rapid improvements, we’re not quite there yet. Although AI naturalists have had some successes, they can also often make basic mistakes. But we shouldn’t be too harsh on the computers, since identifying the correct species just from a picture can be really hard. Ask an experienced naturalist and they’ll often need to know where and when the photo was taken. This information can be crucial for ruling out alternatives. There’s a reason why field guides include range maps!
Currently, most AI identification tools only use an image. So, we set out to see if a computer can be taught to think more like a human, and make use of this extra information.
Using AI to Identify Ladybirds
We tested this out using the UK ladybird survey: a fantastic dataset of tens of thousands of ladybird records and photos. The images were submitted by citizen scientists and verified by (human) experts. Ladybirds (ladybugs in some parts of the world) have been identified as a tough challenge for AI, as many have incredibly diverse colouration patterns – including the invasive Harlequin ladybird.

Despite the common names of many ladybird species (‘two-spot’, ‘five-spot’, ‘seven-spot’… all the way up to the ‘twenty-four spot’), counting the spots only gets you so far! Even for the species where the number of spots is consistent, what if you have a photo with only one side of the specimen? It may be easy for a human to account for spots on the other side, but it’s not so straightforward for an AI.
Another issue is that size is a primary distinguishing feature for ladybirds. But images submitted to recording schemes usually have no defined scale. Although some images are taken next to an improvised scale (such as a coin) there is no chance that the AI could use such a diverse source of information.
To help the AI out, we tested also giving it information on the location and time of year of each record, as well as (by cross-referencing with other databases) recent weather, local habitat data, and information about the experience of the citizen scientist submitting the record.
Incorporating Data From Multiple Sources to Help AI Identify Species
To turn slightly more technical, how can all this information be included in an AI? The most basic approach is to use a filter based on known geographical ranges and time of emergence of adult ladybirds. This can prevent an AI making silly mistakes by reducing the list of options. For example, it won’t claim to identify a polar bear in a photo from a rainforest since it is clearly outside of its known range. This approach is quite a blunt instrument though and lacks nuance. In our ladybird dataset, the species ranges pretty much all overlapped across most of England. Temporally, there were at least some records throughout the year. We needed a better solution.
A more sophisticated approach would be to use the contextual data to build a prior expectation of which species the record is most likely to be. Such an approach is much more flexible and doesn’t rule particular species in or out totally. But it doesn’t fully capture the thought process of a human naturalist. A human would collect and use all of the information associated with the record simultaneously to interpret the image.
The key step we’ve taken in ‘Thinking like a naturalist: Enhancing computer vision of citizen science images by harnessing contextual data‘ is to build an AI to actively synthesise the whole suite of data (image and contextual data) simultaneously. The difference in model architecture is summarised in the diagram below. The key advantage is that it allows the AI to use information in the contextual data to actively understand the features in the image.
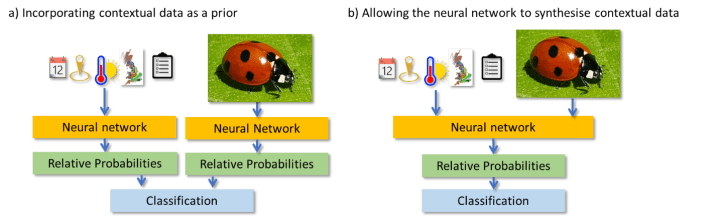 Many species change their appearance or behaviour throughout the year. If certain species are particularly prevalent at a particular time or place, the AI can focus on learning features in images that differentiate just those species.
Many species change their appearance or behaviour throughout the year. If certain species are particularly prevalent at a particular time or place, the AI can focus on learning features in images that differentiate just those species.
It’s difficult to figure out exactly what process led the AI to a conclusion – and that matters since we would like to know how an AI thinks to make sure it is using robust information. One route is to randomise part of the data in the test set and see what makes performance drop the most. For the contextual data, this gave us some reassuring results – in many key cases, it’s clear that the AI has learnt to use very similar pieces of information to those used by human experts.
Practical Uses of AI Identification
As it stands, the accuracy of our AI still lagged behind the humans submitting the records. The citizen scientists were correct in their identification about 90% of the time, while our AI’s best guess was right for about 70% of records. Our aim in this project wasn’t to seek the absolute maximum possible accuracy though. There were a number of tricks (for example showing the AI multiple crops of the image) that we didn’t implement. But there’s still clearly some way to go before AI reaches Pokedex levels of omniscience.
Accuracy is important – it could only take a couple of glaring errors to put people off using an automatic identification app. We’ve shown than synthesising different types of data in the AI will be a valuable part of reaching that goal. Our work gets us a step closer to an AI that can act autonomously, making use of all the information available to human naturalists.
 The ultimate end goal would be to have an app that could give a near-instantaneous identification of a species. iNaturalist’s crowd-sourcing of species identification has had phenomenal success but it includes an inevitable delay between submission and identification. Feedback speed is critical to maximise user engagement and data quality.
The ultimate end goal would be to have an app that could give a near-instantaneous identification of a species. iNaturalist’s crowd-sourcing of species identification has had phenomenal success but it includes an inevitable delay between submission and identification. Feedback speed is critical to maximise user engagement and data quality.
Quick feedback could improve the accuracy of the AI as well. Many of the AI failures were on very low-quality photos. An instant response saying ‘you need to take a better photo’ would be very useful at increasing the value of records. With a quick AI suggestion, a user could confirm an identification by comparing to a reference image. For popular species groups, it’s also conceivable for an app to narrow down the possible species and ask the user a supplementary question to confirm an identification: ‘it is probably Coccinella septempunctata, but check the underside of the specimen to confirm it is not C. magnifica’. This level of involvement and interactivity could drive real engagement with nature.
Give it a go!
As a final aside, machine learning has a reputation of being a fearsome blackbox, only unlockable by computer scientists in the bowels of massive tech firms. But this is just not the case. This project was the result of a three-month NERC-funded placement at the Centre for Ecology and Hydrology, essentially from a standing start – most of the time I work on the ecology of trophic networks, not neural networks!
Full-powered machine learning can be executed through R, familiar to most ecologists. There’s a world of help out on the internet providing resources for getting started. So, if you have a large dataset and want to speed up a monotonous task, machine learning could really help you out!
To find out more, read our Open Access Methods in Ecology and Evolution article “Thinking like a naturalist: Enhancing computer vision of citizen science images by harnessing contextual data“.

One thought on “Teaching Computers to Think like Ecologists”