Spatial Cross-Validation of Species Distribution Models in R: Introducing the blockCV Package
Post provided by Roozbeh Valavi
Modelling species distributions involves relating a set of species occurrences to relevant environmental variables. An important step in this process is assessing how good your model is at figuring out where your target species is. We generally do this by evaluating the predictions made for a set of locations that aren’t included in the model fitting process (the ‘testing points’).
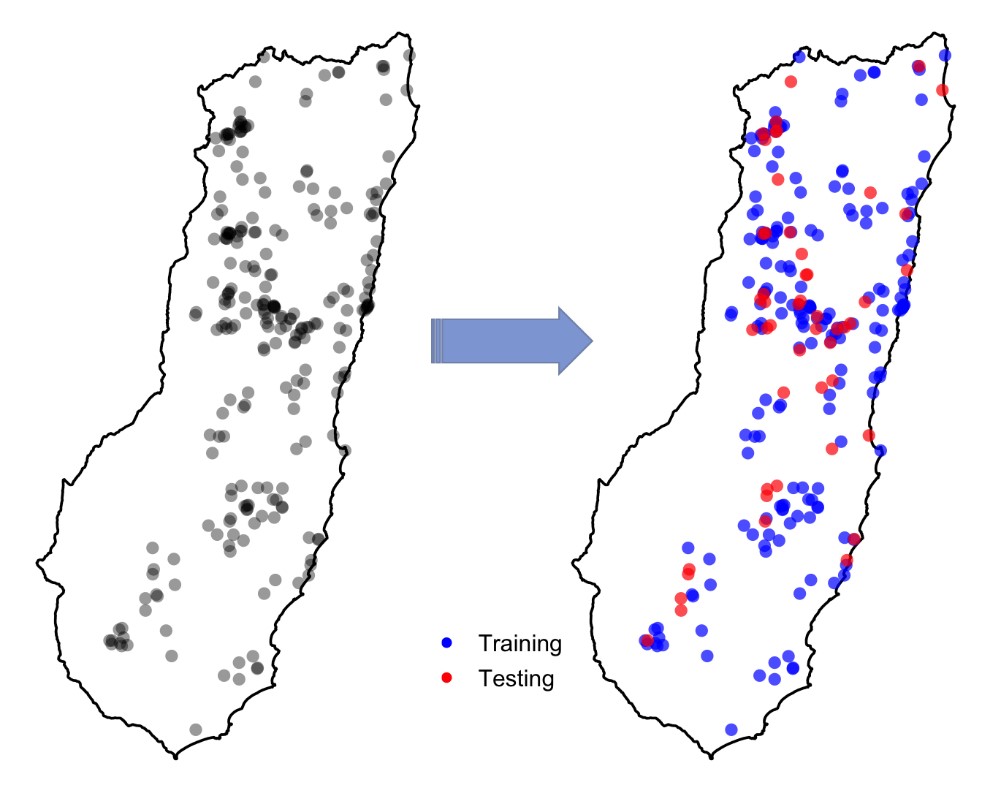
The normal, practical advice people give about this suggests that, for reliable validation, the testing points should be independent of the points used to train the model. But, truly independent data are often not available. Instead, modellers usually split their data into a training set (for model fitting) and a testing set (for model validation), and this can be done to produce multiple splits (e.g. for cross-validation). The splitting is typically done randomly. So testing points sometimes end up located close to training points. You can see this in the figure to the right: the testing points are in red and training points are in blue. But, could this cause any problem? Continue reading “Spatial Cross-Validation of Species Distribution Models in R: Introducing the blockCV Package”

