نویسنده: روزبه وَلَوی
This post is available in English
مدلسازی توزیع گونهها به تخمین و برآورد ارتباط بین مجموعهای از نقاط حضور گونه با متغیرهای زیستمحیطی مرتبط می پردازد. یکی از مراحل اساسی این فرایند، ارزیابی قدرت مدل برای پیشبینی مکانهایی است که احتمال حضورگونه در آنجا وجود دارد. این کار اغلب با ارزیابی پیشبینی انجام شده در مجموعهای ازنقاط که در فرآیند مدلسازی مورد استفاده قرار نگرفته اند (نقاط آزمایشی) صورت میگیرد.
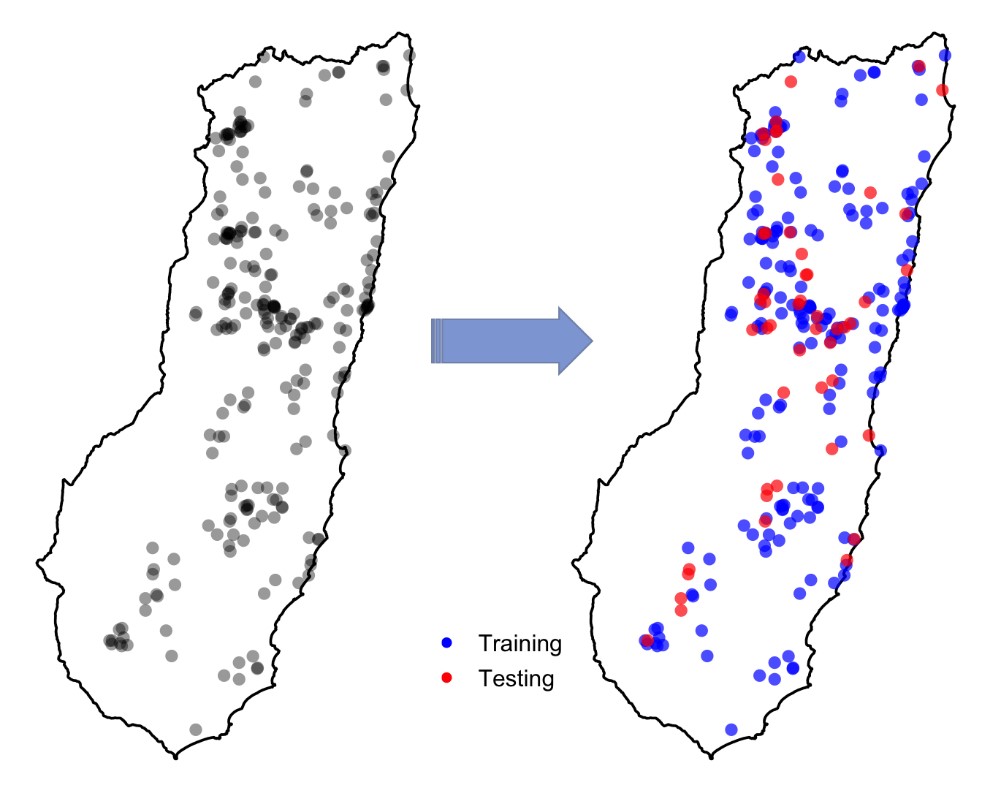
مطالعات پیشین بر این نکته تاکید دارند که به منظور ارزیابی معتبر، نقاط آزمایشی باید مستقل از نقاط آموزشی باشند، این درحالیست که داده مستقل واقعی به ندرت در دسترس می باشد. به همین دلیل، در فرایند مدلسازی معمولا دادههای موجود را به دو قسمت دادههای آموزشی (برای کالیبره کردن مدل) و داده های آزمایشی (برای ارزیابی دقت مدل) تقسیم میکنند، این استراتژی میتواند چند قسمتی هم باشد (برای مثال اعتبارسنجی متقاطع یا cross-validation). از آنجاییکه این تقسیم بندی معمولا بصورت تصادفی انجام میشود، بنابراین گاهی اوقات نقاط آزمایشی در فواصل نزدیک به نقاط آموزشی قرار میگیرند. شکل زیر این مساله را به خوبی نشان می دهد که در آن نقاط آزمایشی به رنگ قرمز و نقاط آموزشی آبی هستند. اما آیا این مساله میتواند مشکلی ایجاد کند؟
مساله خودهمبستگی مکانی
در حقیقت این نزدیک بودن نقاط آزمایشی و آموزشی ممکن است در روند ارزیابی اشکال ایجاد کند. مساله اینجاست که این نوع تقسیم بندی نقاط میتواند منجر به تخمین بیش از حد قدرت پیشبینی مدل شود. این موضوع بخاطر وجود پدیدهای به نام خودهمبستگی مکانی است، به این معنی که نقاط نزدیک دارای خصوصیات مشابهی هستند. از این خصیصه مکانی تحت عنوان قانون اول جغرافیا یاد می شود: همه پدیدهها به همدیگر مرتبط هستند،اما پدیدههای نزدیک بیشتر از پدیدههای دور به هم شباهت دارند!
وقتی نقاط آزمایشی و آموزشی در کنار یکدیگر قرار میگیرند، بدلیل وجود خودهمبستگی مکانی خصوصیات نقاط آزمایشی شبیه نقاطی خواهد بود که در فراینده مدلسازی توسط مدل دیده شدهاند (نقاط آموزشی)، بنابراین پیشبینی این نقاط برای مدل آسان است. در نتیجه، اعتبارسنجی مدل برای نقاط دورتر خوشبینانهتر خواهد بود.
برای رفع این مشکل، نقاط آزمایشی و آموزشی باید به اندازه کافی (در فضای جغرافیایی یا محیطی) از هم دور باشند تا به ارزیابی مدل، دادههای مستقلتری ارائه دهند. آسانترین روش برای انجام این کار تقسیم کردن نقاط بر اساس طول و عرض جغرافیایی آنها است، به عبارتی دیگر، تقسیم منطقه مورد مطالعه به واحدها یا بلوکهای مکانی و تخصیص دادههای درون آنها به فولدهای اعتبارسنجی متقاطع. فرآیند ارزیابی مدل با فولدهای ساخته شده در این حالت را اعتبارسنجی متقاطع بلوکی (block cross-validation) مینامند. (Roberts و همکاران مقاله جالبی درباره این تکنیک و کاربردهای آن در انواع دادههای اکولوژیکی نوشتهاند).

انجام این فرایند با چالش های ویژه ای همراه است. ساخت بلوکهای مکانی و تخصیص دادهها به فولدهای اعتبارسنجی متقاطع میتواند زمانبر باشد و در بسیاری از موارد به آسانی قابل کد نویسی نیست (مثلا زمانی که دادههای گونه بصورت غیر منظم در سطح منطقه مورد مطالعه پراکنده شدهاند). کتابخانه blockCV در نرمافزار R یک ابزار جدید است که این فرآیند را تسهیل میکند. این کتابخانه به سه روش مختلف بلوکهای مکانی، محیطی و بافر میتواند فولدهای اعتبارسنجی متقاطع تولید کند.
این کتابخانه همچنین دارای ابزاری جهت بررسی دامنه تاثیرگذار خودهمبستگی مکانی در متغیرهای پیشبینی کننده است که به کاربر کمک میکند که قبل از هر گونه مدلسازی یک اندازه اولیه برای بلاکهای مکانی انتخاب کند. ابزارهای تعاملی آن (دارای رابط گرافیکی) برای بررسی تخصیص دادههای گونه به فولدها، انتخاب اندازه بلوکهای مکانی و تاثیر آن در نحوه قرار گیری دادههای گونه در این بلوکها مورد استفاده قرار میگیرند. این کتابخانه انتخاب های متفاوتی برای ساخت بلوکهای مکانی و تخصیص دادههای گونه به فولدهای اعتبارسنجی متقاطع ارائه می دهد. در اینجا به معرفی برخی از قابلیتهای آن میپردازیم. برای اطلاعات بیشتر در باره استراتژیهای موجود در این بسته نرمافزاری لطفا مقاله ما را در این مورد مطالعه فرمایید (این مقاله بصورت رایگان از سایت مجله قابل دانلود است).
انتخاب اندازه بلوک مکانی بر اساس خودهمبستگی مکانی موجود در دادهها

یکی از چالش های موجود در اعتبارسنجی متقاطع مکانی، تعیین اندازه بلوک مکانی برای جداسازی دادههای آموزشی و آزمایشی است. رویکرد معمول، سنجش خودهمبستگی مکانی و دامنه آن در باقیمانده مدل میباشد، هرچند بدست آوردن باقیماندهها به اجرای مدل نیاز دارد. برای تسهیل انتخاب اندازه بلوک مکانی قبل از هر گونه مدلسازی، کتابخانه blockCV دارای ابزای برای اندازگیری دامنه تاثیر خودهمبستگی مکانی در متغیرهای پیشبینی کننده است که نشان دهنده ساختار مکانی موجود در آن ناحیه جغرافیایی میباشد.
انتخاب اندازه بلوکهای مکانی بر اساس انتخاب کاربر

اندازه بلوکهای مکانی میتواند به صورت مستقیم توسط کاربر انتخاب شود. جهت نمایش اندازههای مختلف بلوکهای مکانی در سطح منطقه و بررسی نحوه قرارگیری دادههای گونه در این بلوکها، کتابخانه blockCV یک ابراز تعاملی ارائه میدهد. با استفاده از این ابزار شما میتوانید دامنهای از مقادیر را برای اندازه بلوکهای مکانی در نظر بگیرید و با تغییر اندازه نحوه قرارگیری آن بر روی منطقه و قرار گیری دادههای گونه در آن را بصورتی دستی بررسی کنید.
این کتابخانه با هدف ارزیابی مدلسازی توزیع گونهها توسعه داده شده است و فرمت خروجی آن مناسب انواع مدلسازیهای مکانی میباشد، از جمله فرمت مورد قبول برای کتابخانه biomod2، هرچند که انتظار میرود این کتابخانه برای کاربردهای دیگر نیز مورد استفاده قرار گیرد. برای دانلود کتابخانه blockCV و دسترسی به راهنمای آنلاین آن به مخزن گیتهاب مراجعه کنید.
برای اطلاعات بیشتر درباره blockCV مقاله ما را در مجله Methods in Ecology and Evolution مطالعه کنید:

One thought on “اعتبارسنجی متقاطع مکانی در مدلسازی توزیع گونهها”