Post provided by Pritish Chakravarty
Accelerometers, Ground Truthing, and Supervised Learning
Accelerometers are sensitive to movement and the lack of it. They are not sentient and must recognise animal behaviour based on a human observer’s cognition. Therefore, remote recognition of behaviour using accelerometers requires ground truth data which is based on human observation or knowledge. The need for validated behavioural information and for automating the analysis of the vast amounts of data collected today, have resulted in many studies opting for supervised machine learning approaches.

In such approaches, the process of ground truthing involves time-synchronising acceleration signals with simultaneously recorded video, having an animal behaviour expert create an ethogram, and then annotate the video according to this ethogram. This links the recorded acceleration signal to the stream of observed animal behaviours that produced it. After this, acceleration signals are chopped up into finite sections of pre-set size (e.g. two seconds), called windows. From acceleration data within windows, quantities called ‘features’ are engineered with the aim of summarising characteristics of the acceleration signal. Typically, ~15-20 features are computed. Good features will have similar values for the same behaviour, and different values for different behaviours.
To automatically find robust rules to separate behaviours based on feature values, machine learning algorithms (e.g. Random Forest etc) are used. Here, candidate algorithms are trained (i.e. each algorithm is shown which datapoints correspond to which ground truthed behaviours). From here, algorithms are then tested by asking them to classify datapoints they haven’t seen yet into one of the behaviours. How well the algorithm does on testing data determines its ‘performance’. The model with the best performance wins and is selected for final use. Different ways of doing training and testing give rise to different forms of ‘cross-validation’.
Leveraging the Biomechanics Underlying Common Animal Behaviour
All animal behaviour is performed for a finite duration, following which the animal transitions to a different behaviour. The animal may be static for a while (e.g. resting), then begin foraging (involving movement), and then, perhaps perceiving threat, run (involving vigorous, periodic motion). Different behaviours may be performed in different postures (e.g. upright during vigilance, and horizontal while running).
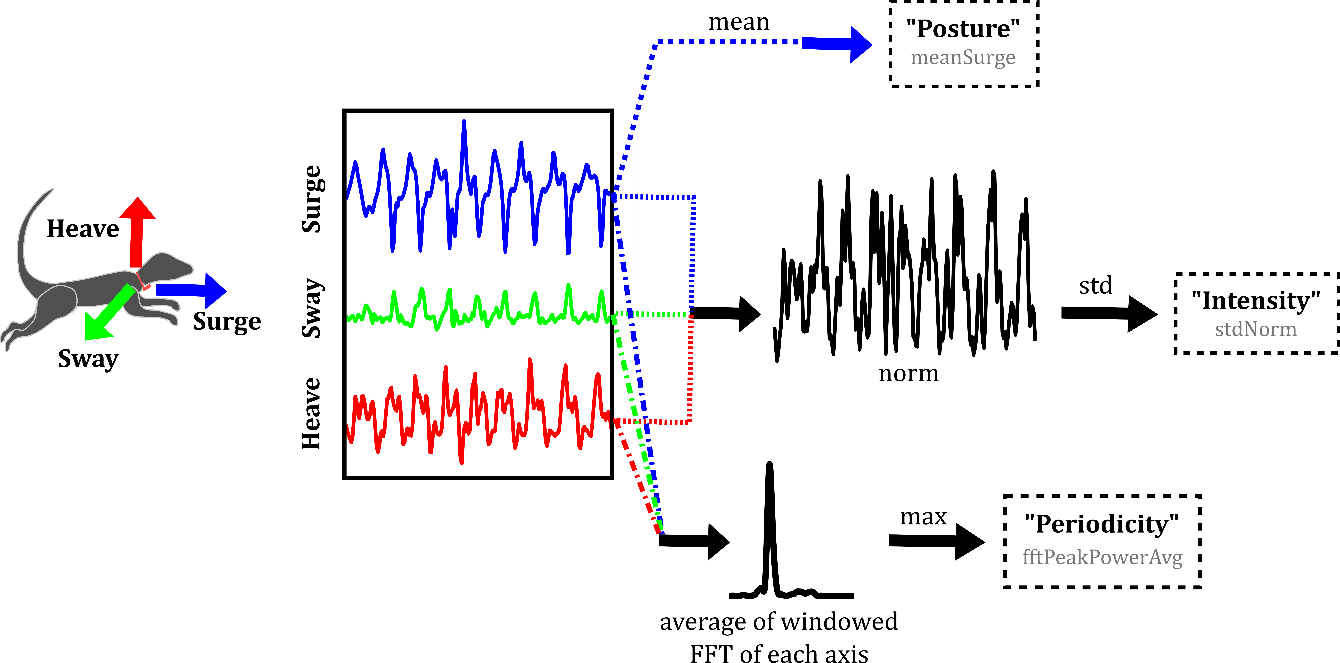
We targeted an ethogram applicable to most animals: resting, foraging, and fast locomotion. This ethogram is a good match between covering most of an animal’s time budget and includes behaviours that an accelerometer is capable of ‘seeing’. For this however, features developed from the accelerometer signal must somehow be able to quantify posture, movement intensity, and movement periodicity. We reasoned that three well-engineered features – one each to quantify the posture, intensity, and periodicity – should be able to tell these three behaviours apart.
Using this approach, we predefined a hierarchical tree-like scheme that classifies broader behavioural categories into increasingly specific ones up to the desired level of behavioural resolution. Each node of this tree uses one or more features tailored to the classification at that node. Robust machine learning algorithms find optimised decision boundaries to separate classes at each node.
We demonstrate the application of this approach on data collected from free-living, wild meerkats (Suricata suricatta). The model accurately recognised common behaviours constituting >95% of the typical time budget: resting, vigilance, foraging, and running.
Model Performance: Leave-One-Individual-Out (LOIO) Cross-Validation
The ultimate goal of many behaviour recognition studies is to build models that will accurately classify data from a new individual previously unseen by the model. Leave-one-individual-out (LOIO) cross-validation is most appropriate to characterise the model’s ability to do this. Here, training is performed using data from all individuals but one, and the left-out individual’s data is used as the testing set. This process is carried out until each individual’s data has been the testing set exactly once.

In other forms of cross-validation, such as validation splits (also called hold out) or 10-fold cross-validation, both training and testing sets contain datapoints extracted from a single continuous recording on the same individual. This violates these methods’ assumption that datapoints are independent and identically distributed, since they are extracted from the same time series. LOIO cross-validation, however, has been shown to mitigate the effects of non-independence of data in human neuroimaging studies. Only one other study has performed LOIO CV (for animal behaviour recognition), and ours is the first study to do so on data from free-ranging, wild individuals.
Reporting Metrics for Each Behaviour Reveals Fuller Picture of Model Performance
Overall accuracy (i.e. the sum of diagonal elements divided by the sum of elements in the confusion matrix), alone can be misleading and uninformative when it comes to characterising model performance in animal behaviour recognition applications. This is because of the issue of imbalanced classes, where durations of continuously filmed behaviours are naturally unequal. This makes the detection of rarer behaviours problematic.
Thus, overall accuracy alone cannot reliably guide model selection. A good model is one that has good sensitivity and precision for each behaviour of interest. This automatically guarantees good overall accuracy, whereas good overall accuracy does not guarantee good behaviour-wise performance.
Benefits of Biomechanically ‘Aware’ Learning
In our paper ‘A novel biomechanical approach for animal behaviour recognition using accelerometers’, we show that the proposed biomechanically driven classification scheme performs better than classical approaches based on black-box machine learning. Further, it is better able to handle the issue of imbalanced classes. Biomechanical considerations in the model can help provide valuable feedback on processes further upstream that are inaccessible to classical machine learning, such as defining the ethogram. The interpretability of the model sheds light on why some classes get consistently misclassified.
Finally, grouping behaviours by biomechanical similarity in a hierarchical classification schemecan allow model sharing between studies on the same species. This eliminates the need to build entire models from scratch every time a new set of behaviours are to be recognised, as would have to be done with classical machine learning approaches.
To find out more about biomechanical approach for animal behaviour recognition, check out our Methods in Ecology and Evolution article, ‘A novel biomechanical approach for animal behaviour recognition using accelerometers’.
This article was shortlisted for the Robert May Prize 2019. You can find out more about the shortlisted articles here.
You can read about the 2019 Robert May Prize Winner here.

Excellent explanation, thanks for the information.
Your blogpost is always very informative and well explained. Thanks for sharing.