Post provided by Matthias Grenié, Emilio Berti, Juan Carvajal-Quintero, Gala Mona Louise Dädlow, Alban Sagouis and Marten Winter.
Merging taxonomic datasets from diverse sources for use in macroecological studies can prove challenging, as there is no standardised methodology, taxonomic names often change over time, and even close colleagues can format the exact same data using different approaches. Researchers at iDiv, the German Centre for Integrative Biodiversity, held a workshop to discuss strategies for harmonizing taxonomy which led to a review of best practice being published in Methods in Ecology and Evolution. In this post, Matthias Grenié and co-authors share insight on this process.
Taxonomy is central for big biodiversity data
As biodiversity science is becoming a data intensive field, more data is becoming accessible to answer new questions. A number of global initiatives such as the Global Biodiversity Information Facility (GBIF) are structuring the landscape of biodiversity data. However, in most cases researchers need to combine the data from different sources to address their questions. In general, this data is indexed at the species scale, because this is the scale which interests most ecologists.

For example, to examine the relationship between plant trait values and the environment, we could combine Red List conservation status to trait data from using the same species name. This makes taxonomy, and the use of species names, central to most questions addressed by merging datasets (also known as “taxonomic harmonization”).
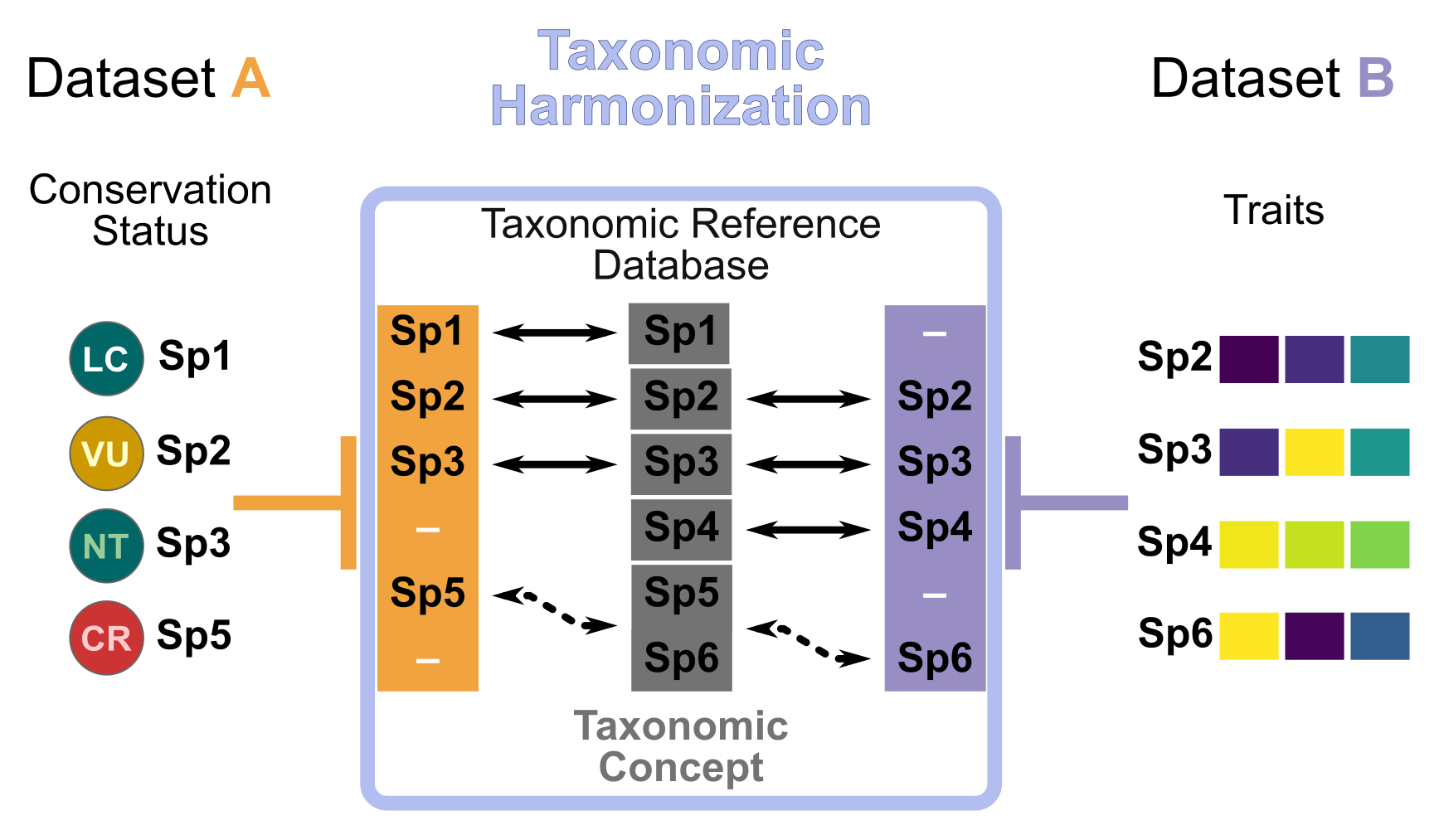
Below is an example of matching two datasets, A and B, through species names. Both datasets do not contain the same species names (Sp1 and Sp5 are only in A, while Sp4 and Sp6 are only in B). However, through the use of a Taxonomic Reference Database, as depicted by the gray rectangles in the center, we can see that both names Sp5 and Sp6 refer to the same taxonomic concept. This means that we can merge the data referred to as “Sp5” in A with data referred to as “Sp6” in B.
However, we soon realized that there was no standard way of using species names to merge datasets. Many macro-ecologists, because they are not trained as taxonomists, are rather users of taxonomy. In practice, some ecologists only merge data for their species of interest if the name matches exactly (same genus, same epithet). But because of the dynamic nature of taxonomy this does not guarantee the best matching, and would be sure to fail (i.e. increased amount of wrong matches) if the initial datasets refer to different taxonomic backbones.
The lack of a guide defining standard practices for taxonomic harmonization, as well as review of the tools to perform harmonization, motivated us to write our article.
Taxonomy changes over time
One difficult issue with taxonomy, is that it is a dynamic scientific topic in itself. Taxonomists routinely discuss, change, and modify taxa names and taxa placements in higher taxonomic levels based on recent scientific discoveries. Thus when a dataset indexes its data based on species names, it does so referring to a specific taxonomy, at a specific time. Depending on the taxonomic group of interest, distinct taxonomies may coexist, and they may change heavily through time. This means that data acquired at different times or across different places can refer to different taxonomies.
So direct matching of species names is risky, as similar species names can refer to different biological species at different times and places! And this is not mentioning homonyms, which are similarly named species referring to actually different species (either on different parts of the tree of life or because binomial names may not be enough to identify a species).
Fortunately, taxonomists made this information available through centralized repositories called “taxonomic reference databases” that try to reflect current discussion and changes per taxonomic group. For example, AlgaeBase is the taxonomic reference database about algae. In general, these are curated by a community of taxonomic experts, who update displayed information based on the latest taxonomic publications. This enormous task of curating taxonomy is often not sufficiently acknowledged. Even if most, if not all, biodiversity data stands on the shoulders of these taxonomic reference databases. Curation is often done by individuals, world leading experts, whom we (and the whole biological community) should be very grateful for. We are specifically grateful to the curators we met in the process of writing our article.

These databases provide information on which species names are considered “valid“ by the taxonomic community, and which others should be considered as “synonyms” or “invalid”. This way, if the taxonomy has been updated compared to when you got your dataset, you can always point back to a valid name.
There are even databases that try to unify taxonomy over more than a single taxonomic group. For example, Catalogue of Life provides the most complete unified taxonomy for the whole tree of life. It does so by merging curated reference taxonomies from different taxonomic groups and branching them on top of each other. It now provides the basic taxonomic backbone for GBIF.
Macroecologists routinely ask questions that need data for hundreds, if not thousands, of species. Manually manipulating the taxonomy for this amount of species would be impractical (and quite cumbersome!). That is why they have to rely on using taxonomic reference databases and tools to extract the taxonomic information directly, standardizing their datasets before actually answering their questions.
Describing taxonomic reference databases and taxonomic tools
Because we couldn’t find a comprehensive review of databases and tools – we decided to build one. There are potentially an infinite number of taxonomic reference databases because they can be as many databases as there are taxonomic groups. Given our other daily tasks, we didn’t (or rather couldn’t due to the sheer amount of information) write an exhaustive review of taxonomic reference databases. We aimed for our article to be read by macro-ecologists like us, so we decided to only include databases that were accessible by R packages.
We identified databases based on two axes: taxonomic scope (small, medium, or large) and spatial scale (regional or global). For example, Catalogue of Life has a large taxonomic scope because it tries to cover all the full tree of life, while AlgaeBase has a smaller taxonomic scope as it is focused on a specific taxonomic group. Both databases consider a global spatial scale because they are not specific to a given region. On the other hand, TAXREF ( has a broad taxonomic scope but it is instead “only” referencing the taxonomy of species occurring in France, so it has a regional spatial focus.
One difficulty we had when trying to understand how taxonomic reference databases worked is that bigger databases (in scale or in scope) are built by aggregating smaller ones. This makes the information available between databases non-independent. It was quite a shock to us that so many databases rely on the same sources. So we tried to uncover as much of the possible links that exist between databases. This was not an easy task, as many databases do not indicate clearly when they are using specific source databases. We thus patiently gathered this information from a mix of database website, database extracts, or direct emails to database maintainers. Again, thanks to all curators who responded and helped us to collect this useful information!
Because we knew our knowledge of taxonomic tools was limited, we tried to write a review as exhaustive as possible about R packages that would help work with taxonomic data. In order to do this we performed extensive searches through CRAN, Bioconductor, and GitHub. We decided to include packages that were only available on GitHub because many useful and popular tools were only available there. Also, getting a package on CRAN is not an easy and trivial task, which might not be accessible to a beginner. This doesn’t render their software less useful, just less accessible. Including GitHub packages also allowed us to reference tools in development that may become the future of taxonomic data wrangling. We should also note that we limited our search to packages in English for the sake of simplicity. So packages had to have at least some documentation in English, though even with this limitation we still included packages to access data from Finnish, Taiwanese, Chinese, and Dutch data.
We ended up identifying a total of 58 R packages. Most packages allowed access to taxonomic information whether on- or offline, few provided basic standard functions to build on top of, and some allowed manipulation of taxonomic data such as computing summary statistics from it.
To summarize most of the information we gathered surrounding tools and databases, we decided to publish a companion shiny app named taxharmonizexplorer that a) displays the network connecting tools between them (tools that rely on one another, databases that use information from one another, and tools that provide access to certain databases), and b) provides some basic information on main characteristics useful when working with those databases and tools. We hope this tool will help users navigate throughout the jungle of taxonomic sources and tools.

Towards a workflow for taxonomic harmonization
The initial problem which triggered us to write our article was not only that a list of sources and tools was not available, but that there was no clear description on how to properly proceed to harmonize and merge datasets. We thus decided to try various approaches in an empirical example to identify best workflows.
We decided to use real world data that some of us were working with: the BioTIME database . It gathers temporal biodiversity data across the world, across all types of ecosystems and taxonomic groups. Given the diversity of species it contains, it would be the perfect candidate to test different workflows. We tested different workflows with pre-processing or not, mobilizing taxon-specific databases or only using databases with a wide taxonomic breadth.
We found a very strong impact of pre-processing which unifies the writing style of species names. It can also catch early spelling mistakes such as double spaces or related input mistakes. Working with taxon-specific databases led to better matches of names, including more synonyms, even though it took longer and complicated the process. Surprisingly to us, using only the GBIF taxonomic backbone resulted in good matches.
We recommend using taxon-specific databases whenever possible to achieve the best taxonomic harmonization. However, when greatest accuracy is not the goal, or when manipulating a diverse set of taxonomic groups relying on bigger databases like Catalogue of Life can make harmonization easier and faster.
Perspectives from our work
We hope we convinced you that taxonomic harmonization is needed whenever you work with more than one dataset using taxa names as a connecting feature. We also provided potential tools that you can leverage to link these data, as well as several strategies on how to do so.
However we only scratched the surface regarding potential workflows because many decisions could affect the quality of taxonomic harmonization (misspelling correction, fuzzy matching, order of databases, leveraging of higher taxonomy, uses of author names), the influence of which have not been well quantified. We wrote guidelines to encourage “best practices” among database curators, package developers, and end-users alike. These communities are all motivated to answer new questions which mobilize taxonomic data. Recognizing the specificities and sometimes divergence of interests would greatly improve the communication to support a better science. For example, specific training workshops to increase the taxonomic knowledge of end-users could be helpful, as well as workshops to make database curators realize how end-users mobilize their data.
To read the full Methods in Ecology and Evolution article, follow the link below:
Harmonizing taxon names in biodiversity data: a review of tools, databases, and best practices.
