Demography and Big Data
Post provided by BRITTANY TELLER, KRISTIN HULVEY and ELISE GORNISH
Follow Brittany (@BRITTZINATOR) and Elise (@RESTORECAL) on Twitter
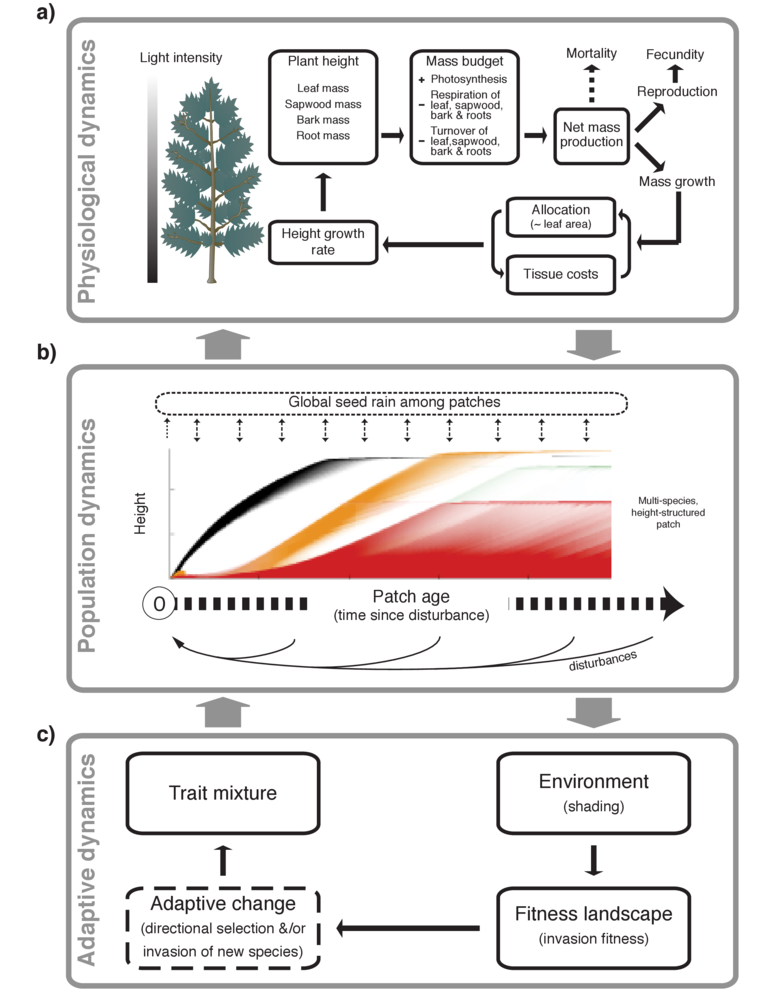
To understand how species survive in nature, demographers pair field-collected life history data on survival, growth and reproduction with statistical inference. Demographic approaches have significantly contributed to our understanding of population biology, invasive species dynamics, community ecology, evolutionary biology and much more.
As ecologists begin to ask questions about demography at broader spatial and temporal scales and collect data at higher resolutions, demographic analyses and new statistical methods are likely to shed even more light on important ecological mechanisms.
Population Processes

Traditionally, demographers collect life history data on species in the field under one or more environmental conditions. This approach has significantly improved our understanding of basic biological processes. For example, rosette size is a significant predictor of survival for plants like wild teasel (Werner 1975 – links to all articles are at the end of the post), and desert annual plants hedge their bets against poor years by optimizing germination strategies (Gremer & Venable 2014).
Demographers also include temporal and spatial variability in their models to help make realistic predictions of population dynamics. We now know that temporal variability in carrying capacity dramatically improves population growth rates for perennial grasses and provides a better fit to data than models with varying growth rates because of this (Fowler & Pease 2010). Moreover, spatial heterogeneity and environmental stochasticity have similar consequences for plant populations (Crone 2016). Continue reading “Demography and Big Data”




 Opportunities at the Interface between Ecology and Statistics
Opportunities at the Interface between Ecology and Statistics

