When we were putting together the British Ecological Society’s Guide to Reproducible Code we asked the community to send us their advice on how to make code reproducible. We got a lot of excellent responses and we tried to fit as many as we could into the Guide. Unfortunately, we ran out of space and there were a few that we couldn’t include.
Luckily, we have a blog where we can post all of those tips and tricks so that you don’t miss out. A massive thanks to everyone who contributed their tips and tricks for making code reproducible – we really appreciate it. Without further ado, here’s the advice that we were sent about making code reproducible that we couldn’t squeeze into the Guide:
“Don’t overwrite data files. If data files change, create a new file. At the top of an analysis file define paths to all data files (even if they are not read in until later in the script).” – Tim Lucas, University of Oxford
“Keep one copy of all code files, and keep this copy under revision management.” – April Wright, Iowa State University
“Learn how to write simple functions – they save your ctrl c & v keys from getting worn out.” – Bob O’Hara, NTNU
“For complex figures, it can make sense to pre-compute the items to be plotted as its own intermediate output data structure. The code to do the calculation then only needs to be adjusted if an analysis changes, while the things to be plotted can be reused any number of times while you tweak how the figure looks.” – Hao Ye, UC San DiegoContinue reading “Making YOUR Code Reproducible: Tips and Tricks”
The way we do science is changing — data are getting bigger, analyses are getting more complex, and governments, funding agencies and the scientific method itself demand more transparency and accountability in research. One way to deal with these changes is to make our research more reproducible, especially our code.
Although most of us now write code to perform our analyses, it’s often not very reproducible. We’ve all come back to a piece of work we haven’t looked at for a while and had no idea what our code was doing or which of the many “final_analysis” scripts truly was the final analysis! Unfortunately, the number of tools for reproducibility and all the jargon can leave new users feeling overwhelmed, with no idea how to start making their code more reproducible. So, we’ve put together the Guide to Reproducible Code in Ecology and Evolution to help. Continue reading “A Guide to Reproducible Code in Ecology and Evolution”
Reproducible research is important for three main reasons. Firstly, it makes it much easier to revisit a project a few months down the line, for example when making revisions to a paper which has been through peer review.
Secondly, it allows the reader of a published article to scrutinise your results more easily – meaning it is easier to show their validity. For this reason, some journals and reviewers are starting to ask authors to provide their code.
Thirdly, having clean and reproducible code available can encourage greater uptake of new methods. It’s much easier for users to replicate, apply and improve on methods if the code is reproducible and widely available
Throughout my PhD and Postdoctoral research, I have aimed to ensure that I use a reproducible workflow and this generally saves me time and helps to avoid errors. Along the way I’ve learned a lot through the advice of others, and trial and error. In this post I have set out a guide to creating a reproducible workflow and provided some useful tips. Continue reading “Making Your Research Reproducible with R”
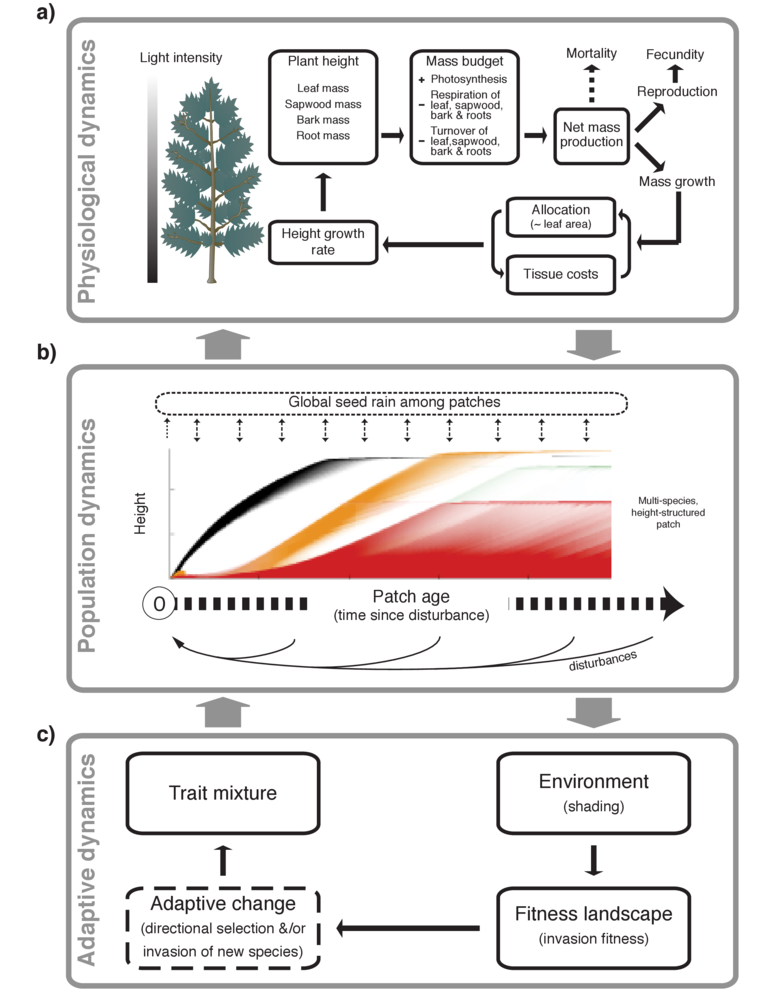
Our paper in Methods in Ecology and Evolution describes a new software package, plant. plant is an individual-based simulation model that simulates the growth of individual trees, stands of competing plants, or entire metacommunities under a disturbance regime, using common physiological rules and trait-based functional trade-offs to capture differences among species.
Non-Linear Processes and Thousands of Plants
Since the development of gap models in the 1970s (e.g. Botkin 1972), researchers have been using computer simulations to investigate how elements of plant biology interact with competition and disturbance regimes to influence vegetation demography, structure and diversity. Simulating the competitive interactions among many thousands of plants, however, is no easy task.
Despite widespread recognition of the importance of key non-linear processes — such as size-structured competition, disturbance, and trait-based trade-offs — for vegetation dynamics, relatively few researchers have been brave (or daft) enough to try and incorporate such processes into their models. The situation is most extreme in theoretical ecology, where much contemporary theory (e.g. coexistence theory, neutral theory) is still built around completely unstructured populations.
Features of plant
Key processes modelled within the plant package.
The plant package attempts to change that by providing an extensible, open source framework for studying trait-, size- and patch-structured dynamics. One thing that makes the plant model significant is the focus on traits. plant is one of several attempts seeking to integrate current understanding about trait based trade-offs into a model of individual plant function (see also Moorcroft et al 2001, Sakschewski et al 2015).
A second feature that makes the plant software significant, is it that is perhaps the first example where a computationally intensive model has been packaged up in a way that enables widespread usage, makes the model more usable and doesn’t sacrifice speed.
 Following on from our sponsorship of the Guide to Reproducible Code in Ecology and Evolution and our collaboration with rOpenSci, we have now released a new policy on publishing code. The main objective of this policy is to make sure that high quality code is readily available to our readers.
Following on from our sponsorship of the Guide to Reproducible Code in Ecology and Evolution and our collaboration with rOpenSci, we have now released a new policy on publishing code. The main objective of this policy is to make sure that high quality code is readily available to our readers.